
Introduction
Data scientist follow a structure of obtaining data, cleaning it, and then feeding it through one of their many fancy models to determine which one has the best “predictive” capabilities. This insight is highly valued by many companies either as a means to have some foresight into future conditions or revise current systems to increase efficiency and profit. One example of a widespread use of this data is for credit card fraud detection.

Contrary to what some may believe, the handwriting of one’s signature on an electronic pad is not likely a heavy determinant on whether or not fraud has been committed, especially since online purchases do not require this signature. Instead, to determine fraud, credit card companies can look at many factors for a single transaction: attributes like where the purchase occurred, what items were bought, the timing of the purchase, and the relationship between that purchase and past purchases are all examples of what need to be accounted for.
Precision, Recall, Accuracy, and F1
Considering how often Americans use their credit card, credit companies have to be able to sift through a massive amount of data to identify if any single transaction could be made fraudulently. For these types of identification problems, data scientist use a few different parameters to determine the efficacy of their models (Assume that a positive result is an indication of fraudulent behavior):

The equations above can be a bit confusing, but here’s a breakdown of the difference between each term.
- Precision – Decreases only when the model identifies a legitimate transaction as a fraudulent transaction.
- Recall – Decreases only when the model identifies a fraudulent transaction as a legitimate transaction.
- Accuracy – How many things did the model identify right as a whole?
- F1-Score – More or less just a way to balance out the weight of both precision and recall to make both items more equally important
In the case of credit card companies, these metrics do not carry equal importance because the monetary loss is heavily tied with one specific metric–recall. This make sense as accepting a fraudulent transaction as legitimate potentially leads to a substantial economic cost. Conversely, flagging a transaction as fraudulent can simply be rectified by checking in with a client and leads to little resource usage. Classification problems like these are ubiquitous in every field such as medicine, for example, where cancers might need to be classified as malignant or benign. Thus, the ability to have machines help us decide is invaluable.
Automated Machine Learning
Machine learning is highly efficient, being able to parse through multitudes of data and abstract information. Data scientists rely on many algorithms to create their model, testing and tweaking certain parameters to fine tune each model. This process, however, can be a bit tedious as they must decide which models to use and which parameters to tweak. Therefore, the next logical step would be to automate the whole process itself. Enter automated machine learning (Auto ML, for short).
As the name suggest, auto ML takes much of the grunt work out of having to have to decide which algorithmic model to use and which parameters to adjust. After inputting a few parameters, auto ML is able to run through many different types of machine learning and deep learning models to find the best one. This is extremely convenient as it lowers the technical barrier for business and organizations that want to be able to understand their data without having to hire a specialized employee or consultant.
Google, Amazon, Microsoft and many other big tech companies have already heavily invested in this new technology. For the aspiring data scientist, there is hope still, as some technical expertise is always needed to fine tune model, and there are still some downfalls with auto ML.
AutoML with H2O
There are a number of well-known auto ML platforms and libraries (see here for more details). The one we’ll focus on today is autoML, which proves easy to install and use (refer here for installation guide). This walk-through will also rely on the credit card fraud dataset from Kaggle. To begin, simply import the packages and initiate an H20 cluster:
import h2o from h2o.automl import H2OAutoML #initiate cluser h2o.init()
Preprocessing the data is actually an optional step, as H2O handles unprocessed data rather well. Be sure to refer to the documentation as there are many useful optional parameters that can help process the data as the cluster runs.
Then, convert the pandas dataframe into a H2O dataframe and declare the target variable as a classification. H2O will otherwise treat it as a regression problem:
#turn pandas to h2o dataframe dataframe = h2o.H2OFrame(df) #make sure the target is categorical dataframe[target] = dataframe[target].asfactor() #Declare the x- and y- variables for the database. #x-variables are predictor variables, and y-variable is what #we wish to predict x = dataframe.columns y = target #remove the target feature from the x columns x.remove(y)
Now to just split the H2O dataframe into training and test sets (validation optional) and plug it into the cluster:
#Pull the training and test data out at a 80/20 split. train, test = dataframe.split_frame(ratios=[.8, .2]) # Run AutoML for N base models (limited to 1 hour max runtime by default); set the metric to AUC aml = H2OAutoML(max_models=10, sort_metric = 'AUC', seed=117) aml.train(x=x, y=y, training_frame=train)
*In the above example, I limited the auto ML to 10 models and decided to rank the models according to the best AUC.
Use the following to print the leaderboard:
# View the AutoML Leaderboard lb = aml.leaderboard #this prints out ALL models. You can specify how many with rows=number print(lb.head(rows=lb.nrows))
This will output the following (or something similar):
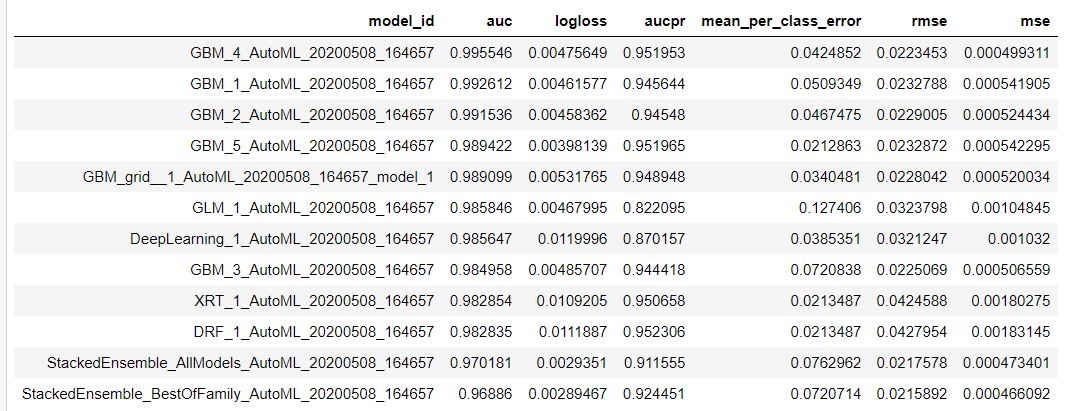
To view details of the leading model:
h2o_aml.leader
This will provide an extensive output of metrics on how the leading model performed including some of the following:
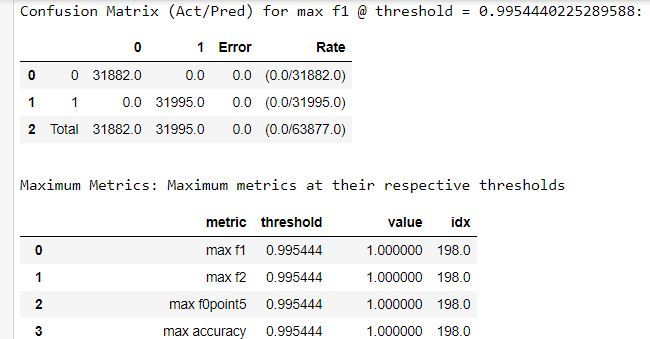
Lastly, testing the leading model against the test data is a familiar step. Be sure to convert the test pandas dataframe into an H2O dataframe first:
#Get performance on test data after converting to H2O dataframe test_h2o = h2o.H2OFrame(test) h2o_aml.leader.model_performance(test_data=test_h2o)
This will output something similar to before:

These steps can easily be reworked into a single function that intakes a dataframe and target variable, which simplifies the entire model selection process.
Pitfalls
Data science is becoming more accessible than ever as tech giants work to simplify the process, so businesses can make use of their data without having to rely on a data professional. However, autoML is still very resource intensive, as running a relatively small dataset through even 10 models can be time consuming.
In addition, autoML platforms and libraries also have many parameters that need to be tweaked to maximize efficiency, so understanding the fundamentals behind key algorithms is still the best way to fine-tune this method. Lastly, certain autoML methods may not work on every platform, which limits widespread application.
