
Classification tasks, such as identifying fraudulent behavior on a credit card, are invaluable to any business or entity. There are many approaches that allow for predicting the class of an unknown object, from simple algorithms like Naive Bayes to more complex ones like XGBoost.
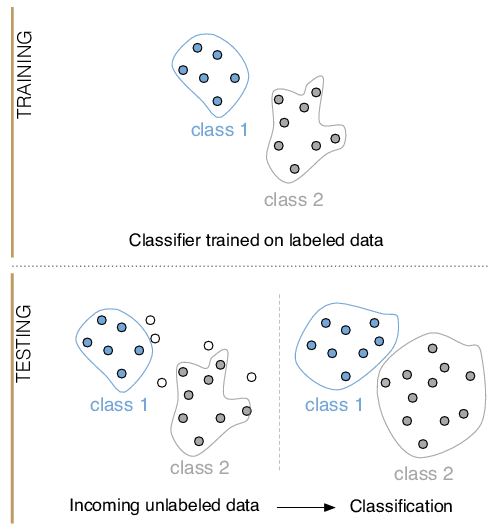
However, for most (if not all) of these approaches to modeling data, external input is still needed from the user. This is because while the algorithm can learn based on the supplied data, how it learns must be predetermined via hyperparameters, which are inputs used to sway and control the learning process of the algorithm. This is critical because while algorithms may split training data in similar manners, how they fare with future data depends on the given hyperparameter.
For example, with Support Vector Machine classification, a key hyperparameter dictating how the algorithm learns is the kernel passed because this affects how SVM draws the boundaries separating each category.
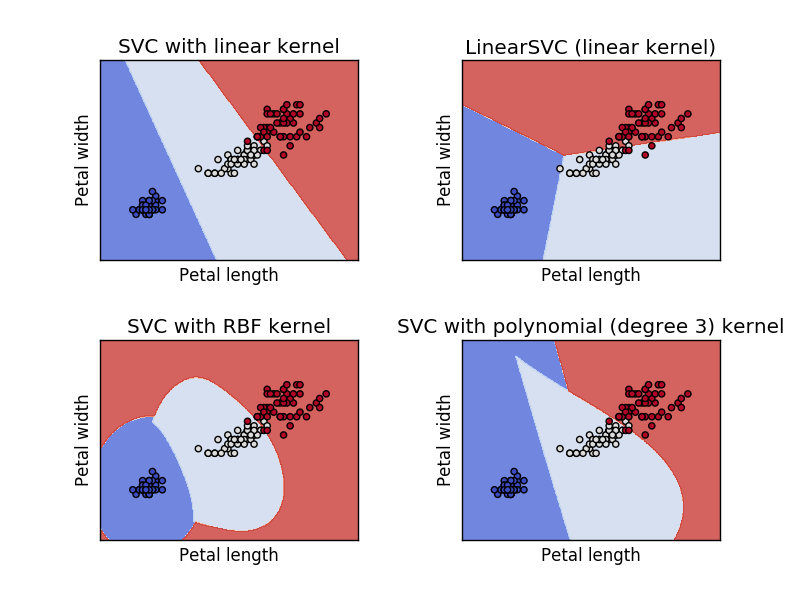
With two dimensions, it may be easy to visually determine which kernel may do best at generalizing the data and trends, but this would be impossible for any dataset with four or more features. Hence, data scientist have to rely on score reports (accuracy, ROC, etc) to determine how well their passed hyperparameter did. If their model performed sub-optimally, then those parameters would need to be adjusted to produce the best model, which still must avoid overfitting. This makes hyperparameter optimization one of the most tedious, yet crucial task for data science today. Hundreds of models and many iterations of adjusting hyperparameters may be necessary before finding a satisfactory model.
Fortunately, there are certain techniques that reduce the amount of time needed to test all combinations of hyperparameters, making it easier to find the optimal model:
- Grid Search : Instead of trying one combination of hyperparameters at a time, grid search allows the user to input a list of hyperparameters to try at once. The function then exhaustively goes through every possible combination of hyperparameters based on the lists the user has given and return the one with the best score (based on standard the model is scored by). The downside is that Grid Search is computationally expensive. Two lists of hyperparameters with 4 values in each will already necessitate 16 different models to be made, fitted, and evaluated. Therefore, it is crucial the the scientist selects the lowest possible number of “reasonable” values to pass into Grid Search.
- Random Search: As the name suggests, this function randomly selects combinations of hyperparameters to apply to the model. Though it sounds rudimentary Random Search can actually outperform Grid Search, especially if there are not many hyperparameters that have a big effect on the final model. In addition, it is done much quicker due to it being non-exhaustive. The disadvantage for both Random and Grid Search is that they are embarrassingly parallel, which means they do not take into account prior combinations that have already been evaluated when running the next combination. Hence, neither function “learns” from itself.
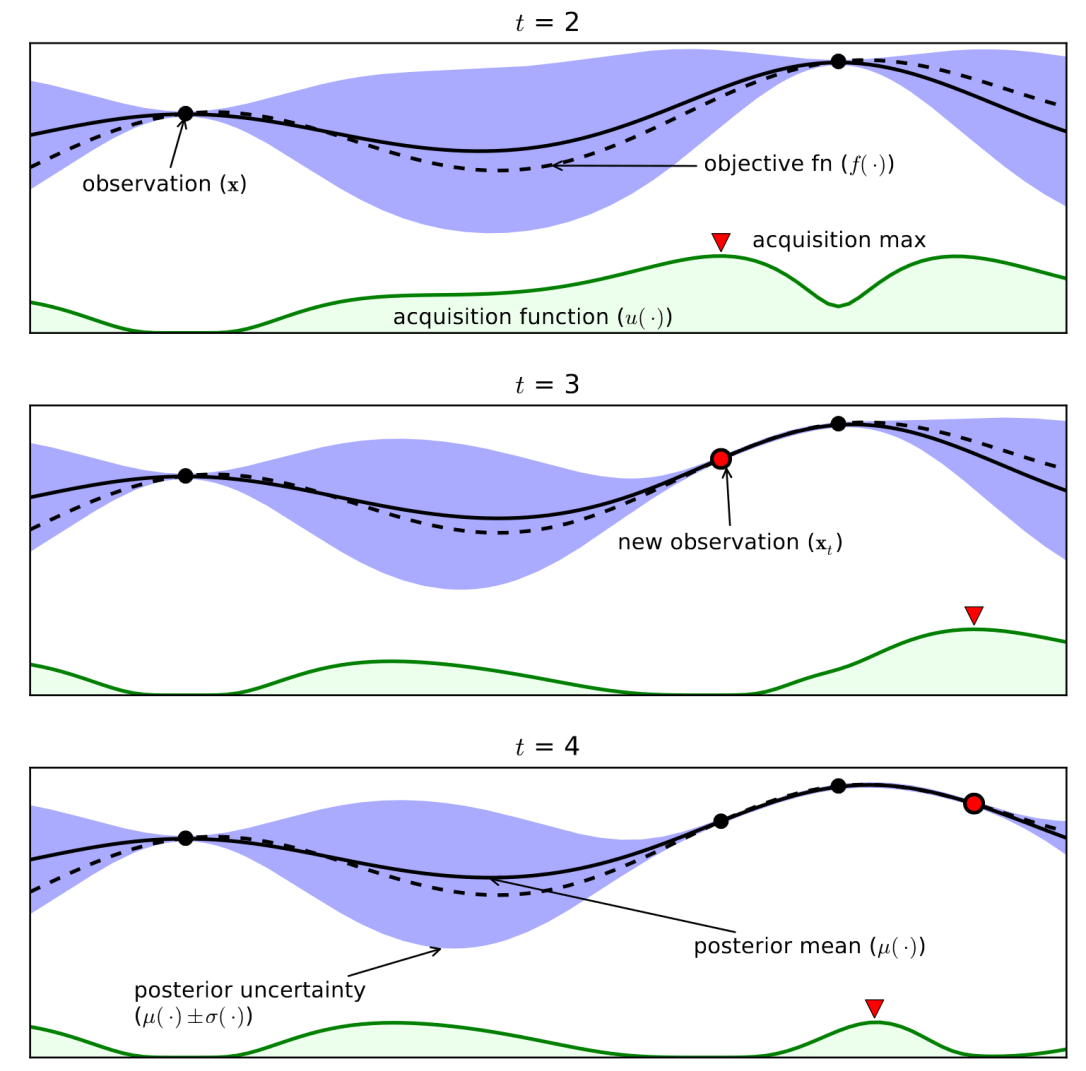
- Bayes Optimization: A range of value can be provided for Bayes Optimization, since the number of iterations can be predetermined by the user. This function is able to form and use an acquisition function to determine the next query point in obtaining the objective function. In short, Bayes Optimization focuses on which parameters could be the closest to optimal without exploring uncertain parameters. Ie. If the function finds that a value of 2 (for whatever hyperparameter) is able to improve the model, then it would be more likely to try a value of 3 next rather than 10. Bayes Optimization tends to do better than Grid Search, since each iteration of a possible combination of parameters is informed by the previous ones. However, since the function tends to be influenced by priors, it does not explore all possible numbers in a given range. Therefore, it is best used iteratively, since it can find a good model with very few iterations.
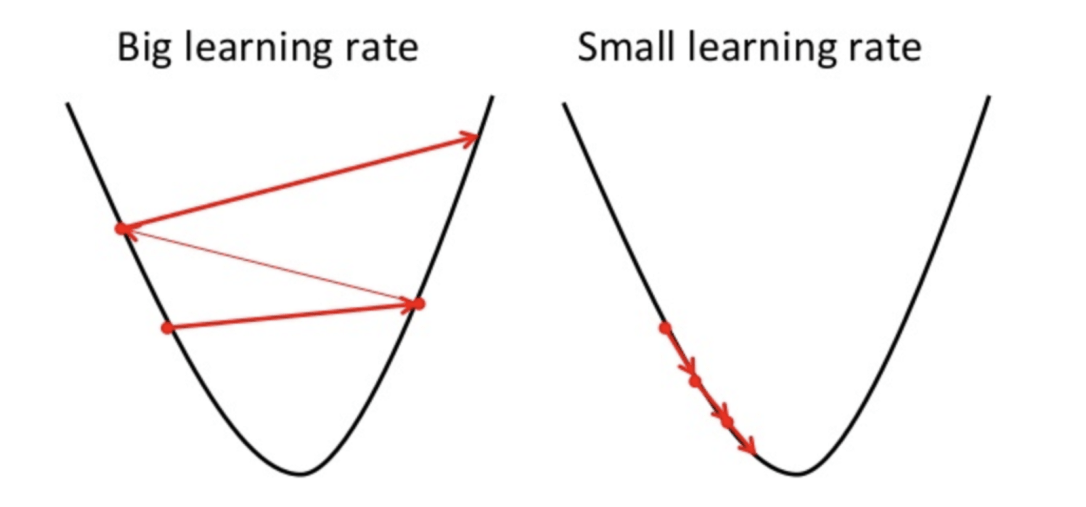
- Gradient-Based Optimization: Since the goal is to iterate through a set of hyperparameters to inch towards the best value, it should be no surprise that hyperparameters can also be optimized using gradient descent. Similar linear regression, it uses a learning rate to go towards the local minimum. However, this means that selecting the correct learning rate is crucial. Too big and the function will overshoot the minimum. Too small and the function may never converge on the minimum. Like other functions above, gradient-based optimization must also be iterative to find the best combination.
There are other methods for hyperparamter optimization, but it is impossible to discuss all of them within the scope of a single paper. The existence and necessity for hyperparameters show both the limitation and potential of modern machine learning. While input from data scientist is still necessary, it is also true that more of the process is becoming automated.
